
20–21 апреля в особняке Кузнецовой прошел первый открытый воркшоп «Изучение языкового разнообразия литературных премий», организованный Центром МАСТ Европейского университета в Санкт-Петербурге. Рассказываем, как это было.
В рамках реализации стратегии Центра МАСТ по развитию исследований с применением методов обработки естественного языка (NLP), мы организовали первый воркшоп, посвященный знакомству с методами NLP. Для более чем двадцати участников воркшопа выступили приглашенные эксперты: Эдуард Клышинский (НИУ ВШЭ), Вероника Зыкова (НИУ ВШЭ), Евгения Заковоротная (НИУ ВШЭ) и Яна Сосновкая (ЕУ СПб). Лекции не ограничивались презентационными материалами, а также включали себя практическую работу с разбором только что представленных методов на практике. Помимо лекционной части участники работали в группах над проектами, направленными на изучение языкового разнообразия. Участников разделили на четыре группы. Работа в группа была организована кураторами (Эдуард Клышинский, Вероника Зыкова, Евгения Заковоротная, Яна Сосновкая, Александр Вильховенко (ЕУ СПб)) таким образом, что перед началом воркшопа каждый участник знал, какая роль в команде ему предписана, и мог выбрать один из предложенных проектов или инициировать свой собственный. Поделимся тем, что получилось у команд в рамках работы над проектами. Более подробные результаты работы команд опубликованы на сайте воркшопа.
Тексты тоже испытывают чувства: проверка преобладания эмоциональной окраски при помощи методов кластеризации
команда проекта: Татьяна Авдеева, Матвей Данилов, Валерия Мелкозерова, Павел Минеев, Лада Скоробагатько.
Команда этого проекта решила поэкспериментировать на текстах русской литературы и драматургии и научиться автоматически определять эмоциональную окраску (тональность) текста.
В рамках предобработки были исключены стоп-слова, проведена лемматизация, а также векторизация при помощи TF-IDF. Для решения задачи классификации были выбран бинарный (распределение результатов на позитивные и негативные) и multilabel (различие слов по спектру эмоций) методы. Первый анализировал тексты по эмоционально окрашенным словам, а для второго использовалась модели из набора Hugging Face. Для определения тональности текста бинарной классификацией, были необходимы эмоционально окрашенные слова. С этим помог датасет – тональный словарь русского языка КартаСлов, который включает в себя более 46 тыс. слов с их значениями силы эмоции из диапазона от -1 до 1 (где -1 это очень негативное, a 1 – очень положительное слово). Далее были удалены все нейтральные слова (те, которые по модулю < 0.8). Также команда использовала кластеризацию методом k-means для того, чтобы распределить тексты на несколько групп и получить разделение на несколько базовых эмоций. Чтобы проверить, насколько релевантно сохранять для классификации только эмоциональные слова, также была проведена multilabel-классификация для тех же текстов, но без удаления нейтральных слов.
Далее была проведена multilabel-классификация с помощью модели RuBERT-tiny2-ru-go-emotions, которая была дообучена для задач классификации по 27 категориям (любопытство, смущение, нервозность, гордость и т.д). Также была проведена автоматическая бинарная классификация с помощью rubert-tiny2-russian-sentiment.
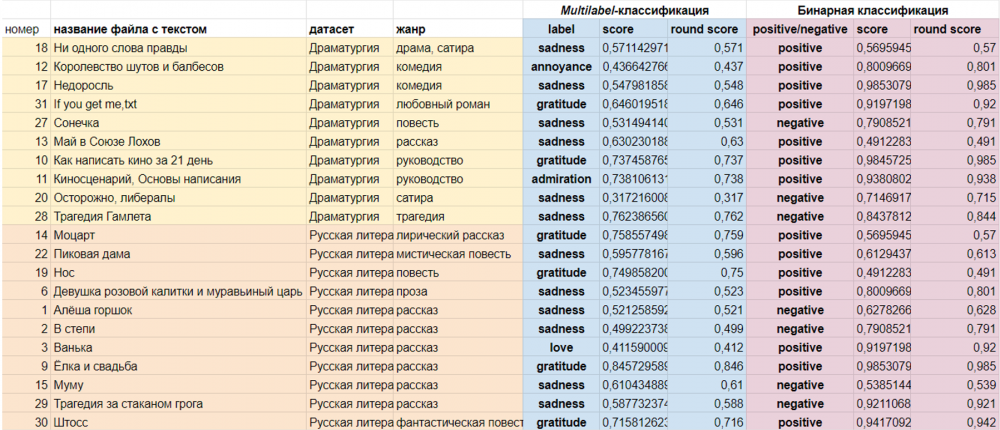
Насколько точным оказался такой метод, еще предстоит исследовать. Однако по значениям метрики score (обозначает, насколько модель уверена в прогнозе), можно заметить, что в среднем, классифицируя текст только по эмоциональным словам, модель сильнее убеждена в точности предсказания. Так, например, рассказ “Муму” в обоих случаях попал в категорию sadness / грусть, но без нейтральных слов score — 0.61, а с нейтральными — 0.4.
Мужское/Женское: у кого больше шансов на победу?
команда проекта: Алена Аспидова, Никита Безыкорнов, София Жиделёва, Александр Ким, Дмитрий Новокшанов.
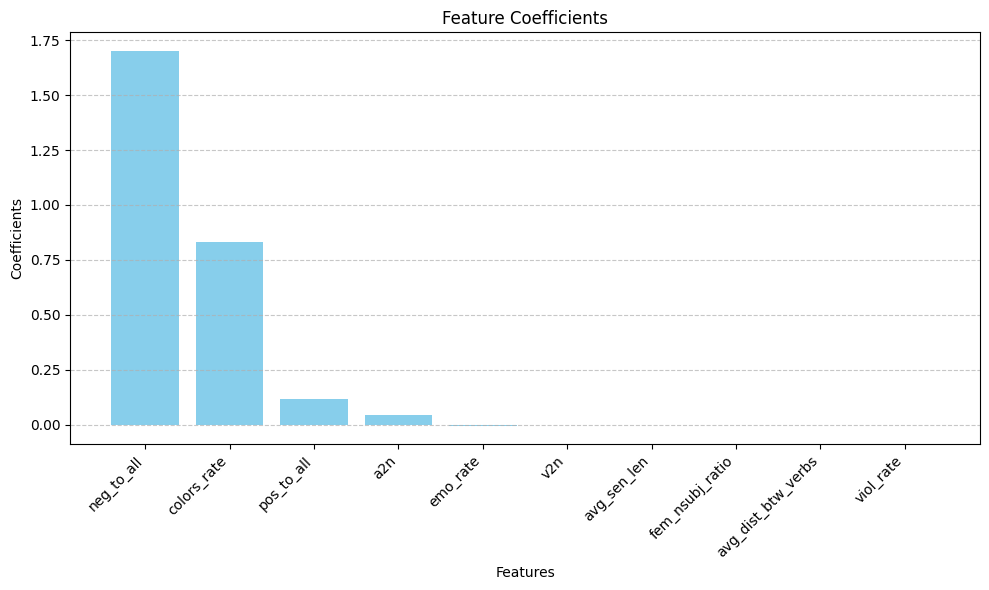
Команда поставила перед собой задачу выяснить, какие отличия и сходства есть (и есть ли вообще) в текстах, написанных женщинами и мужчинами. Команда работала с корпусом данных из 27 текстов, получивших премию «Большая книга». Они подобрали ряд признаков, обучили классификатор и посмотрели, какие признаки модель посчитала важными для разделения текстов на мужские и женские.
По итогам работы команда пришла к выводу, что в отличие от текстов, написанных мужчинами, в текстах, написанных женщинами, содержится больше лексики, связанной с негативными эмоциями и колористическим восприятием (гипотеза, выросшая из стереотипа о том, что женщины лучше различают цвета, подтвердилась).
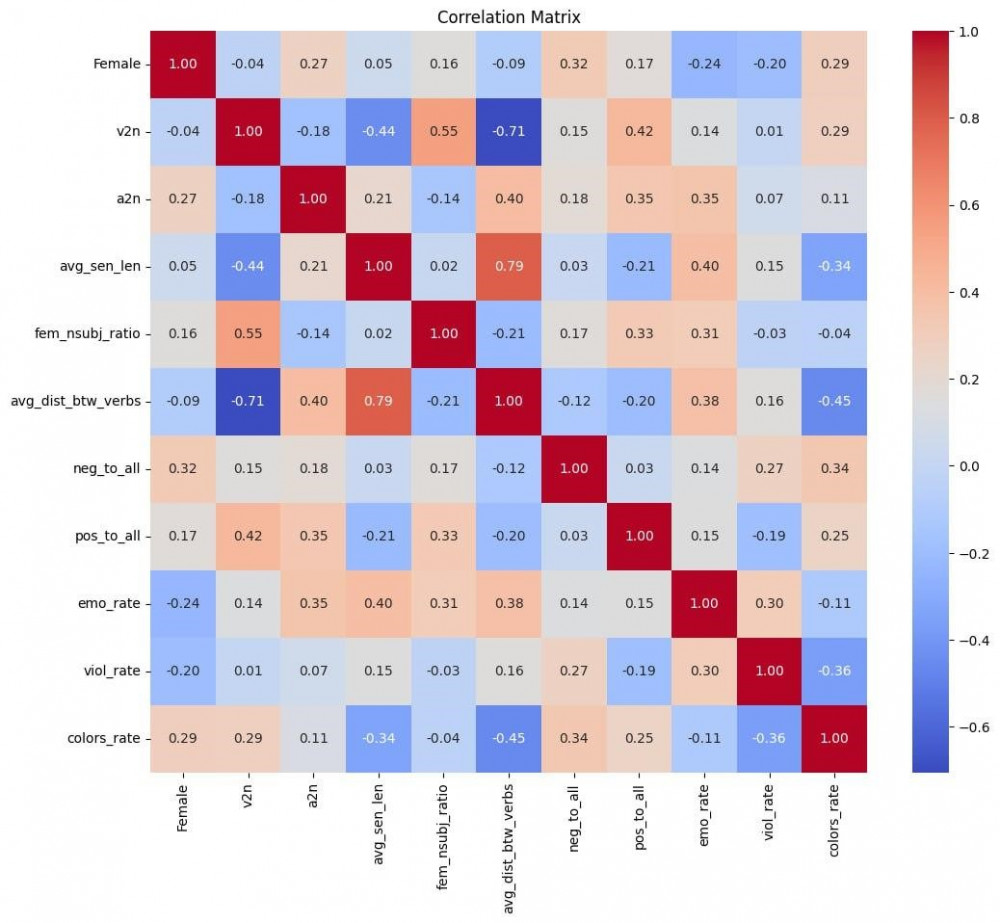
v2n - отношение глаголов к существительным,
a2n - отношение прилагательных к существительным,
avg_sen_len - средняя длина предложений,
fem_nsubj_ratio - отношение женских действующих лиц ко всем действующим лицам,
avg_dist_btw_verbs - средняя расстояние между глаголами (в словах),
neg_to_all - отношение негативно расцененных предложений ко всем предложениям,
pos_to_all - отношение позитивно расцененных предложений ко всем предложениям,
emo_rate - отношение отвечающих за эмоции слов ко всем словам,
viol_rate - отношение отвечающих за домен насилия слов ко всем словам,
colors_rate - отношение слов, описывающих цвета, ко всем словам.
Классики vs Современники: сравнение текстов классических писателей и фанфиков
команда проекта: Елизавета Асташкина, Алина Владимирова, Дмитрий Местковский, Анастасия Янечко.
Команда занималась сравнением работ классических писателей и фанфиков, их задачей было определить, в чём отличия между текстами. Для этого потребовалось вычленить именованные сущности, провести сетевой анализ, а также поработать с синтаксическими структурами текстов, вовлекая в борьбу с текстовой стихией и R, и Python. Базой данных для проекта послужили 372 классических произведения (публицистика, проза, поэзия) и 5318 фанфиков.
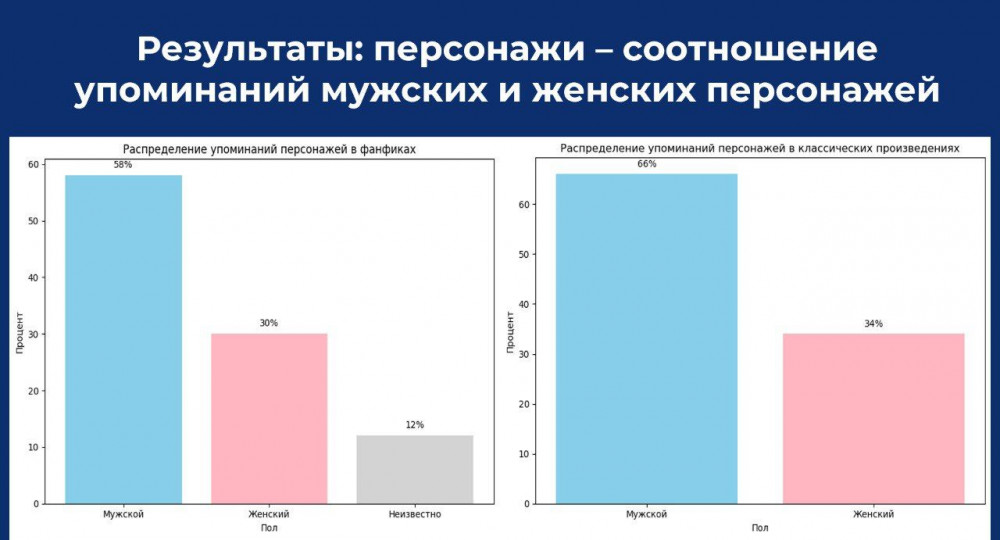
Удивительно, но в фанфиках авторы несколько чаще употребляют более простые предложения, а классические авторы предпочитали усложненные конструкции. При этом синтаксическое разнообразие наблюдается в обеих категориях. Также в среде фанфиков есть ярко-выраженные сообщества Гарри Поттера (самое обширное), Шерлока Холмса, Трех мушкетеров, «Доктора Кто», а также сообщество любителей русских сказок. Главными персонажами являются Гарри Поттер, Гермиона Грейнджер, Северус Снейп. Воедино связывают фандомы «мультивселенные» (персонажи разных книг в одном рассказе) и наличие таких сущностей как «новый мужской персонаж» и «новый женский персонаж», а также «неизвестный персонаж». Изоляты (вершины без связей) вероятно – ориджиналы.

Распределение упоминаний мужских и женских персонажей в классических произведениях и фанфиках схоже, однако в фанфиках встречаются персонажи, которых нельзя идентифицировать однозначно (например, «Горный цветок»).
И я литературную премию хочу!
команда проекта: Ксения Золина, Георгий Катречко, Илья Конов, Денис Савельев, Алиса Семенова.
Целью этого проекта стало обучение модели генерации, которая будет создавать тексты, которые потенциально могли бы получить премию. Сначала команда провела дообучение модели ruGPT3 small (gpt2)(прототип - ai-forever/rugpt3small_based_on_gpt2) на корпусе текстов книг лауреатов литературной премии, затем разработала классификатор (прототип - cointegrated/rubert-tiny2), который разделял тексты на 4 класса:
4 - Тексты, получившие литературную премию;
3 - Хорошие тексты авторов, не получивших премию;
2 - Плохие тексты;
1 - Фанфики.
Для того чтобы в генерируемых текстах сохранялся контекст, был подготовлен суммаризатор (прототип - sarahai/ruT5-base-summarizer). После чего вс вышеперечисленное было объединено в псевдо-GAN функцию, т.к. GAN – это про параллельное обучение генеративной и дискриминантной модели, а у нас есть только дискриминация на этапе инференса. На изображениях ниже можно увидеть результаты работы модели после ее часового обучения.

Мы благодарим участников, приглашенных экспертов, наших коллег за доверие и участие в первом воркшопе Центра МАСТ и надеемся на новые встречи!