
23–24 ноября в Европейском университете состоялся второй воркшоп Центра МАСТ «Кино и тексты: анализ сценариев лауреатов кинопремий». Делимся впечатлениями и первыми результатами.
Центр МАСТ во второй раз проводит воркшоп, посвященный изучению и применению методов обработки естественного языка (NLP). Темой этого воркшопа стало изучение сценариев кино и сериалов. Организаторы подготовили несколько датасетов, состоящих из сценариев, в т.ч. лауреатов кинопремий, а участники попробовали исследовать эти тексты с помощью методов NLP в рамках групповых проектов. Мероприятие прошло в рамках реализации стратегии Центра МАСТ по развитию исследований с применением методов обработки естественного языка.
На протяжении двух дней участники прослушали лекции экспертов, работали в группах с кураторской поддержкой и представили результаты работ над своими проектами.
В первый день воркшопа Елена Михалькова (ЕУ СПб) рассказала о том, какие исследования можно проводить на сценариях, а Ника Зыкова (НИУ ВШЭ) поделилась тем, как использовать языковые модели Hugging Face для работы со сценариями. После чего участники начали работу над групповыми проектами, в этом им помогали: Яна Сосновская (ЕУ СПб), Алексей Сенюхин (ЕУ СПб), Александр Вильховенко (ЕУ СПб), Эдуард Клышинский (НИУ ВШЭ), Павел Ефимов («Huawei») и Ника Зыкова. Первый рабочий день завершился лекцией Эдуарда Клышинского, посвященной обзору методов извлечения полезной информации из текстовых данных.
Второй день начался с лекции Павла Ефимова об анализе тональности разговорных данных, лекционную часть продолжил Александр Вильховенко, который рассказал о воспроизводимости научных результатов и обсудил с участниками воркшопа, почему отсутствие значимых результатов – тоже результат. Оставшееся время участники провели за работой над групповыми проектами. Завершением воркшопа стала презентация результатов работ групп.
В своих групповых проектах участники пробовали решить широкий ряд задач с помощью методов NLP: начиная от распределений эмоций в сериалах, заканчивая тем, чтобы при помощи NLP узнать все, что можно о сценарии, не читая его.
Мы подготовили сайт, на котором можно узнать подробности групповых проектов и работы на воркшопе.
Скажи мне три фразы, и я скажу, кто ты
команда проекта: Мария Бурлак, Евгения Лепихина, Марина Севостьянова, Екатерина Федорищева, Людмила Шляхтина.
Команда этого проекта хотела узнать, можно ли только по семантике реплик дать персонажу характеристику: является он положительным или отрицательным, главным или второстепенным. Команда работала на датасете сценариев фильмов франшизы о «Гарри Поттере».
Коллеги вручную разметили персонажей, векторизировали их реплики, обучили модель выполнять эту задачу и попробовали применить ее на другом датасете.
Ещё перед тем, как обучить модель, команда решила посмотреть на наши данные с помощью UMAP и узнать сразу, есть ли какие-то закономерности. Для начала команда взяла «goodness» персонажей и получила результат с левой диаграммы на рисунке ниже — хорошие и плохие персонажи не разделились. Стало понятно, что персонажи с разными характеристиками говорят об одном и том же. И после того, как коллеги создали собственные векторы, результат стал иным – между ними появилось какое-то различие.
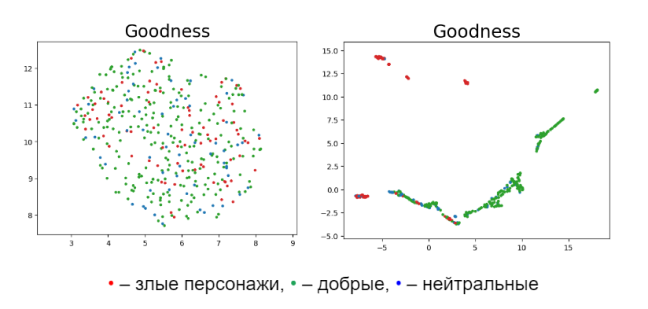
По итогам работы точность обученной модели по положительности персонажей составила 67%. Модель относительно хорошо справляется с положительными персонажами (F1-мера составила 80%), однако плохие и нейтральные персонажи вызывают у неё сильные затруднения (26% и 19% соответственно).
От меня ничего не скрыть
команда проекта: Анфиса Алексеева, Арина Букина, Анна Бухарова, Елизавета Елисеева, Павел Минеев.
Коллеги из этой команды задались целью узнать, что можно рассказать о сценариях, не читая его. Другими словами, какие неочевидные данные можно вытащить из датасета? Свою работу они провели на датасете по мультсериалу «Аватар: Легенда об Аанге».
Анализ показал, что герои делятся на несколько групп по длительности и непрерывности появления. Например, главные герои, такие как Аанг и его команда, доминируют на протяжении всех серий, в то время как второстепенные персонажи и антагонисты появляются эпизодически, но их арки сосредоточены в определенных моментах сюжета. На графике ниже показано изменение среднего сентимента (по шкале AFINN) реплик главных героев каждой серии, что позволяет оценить эмоциональную динамику их диалогов на протяжении сюжета.
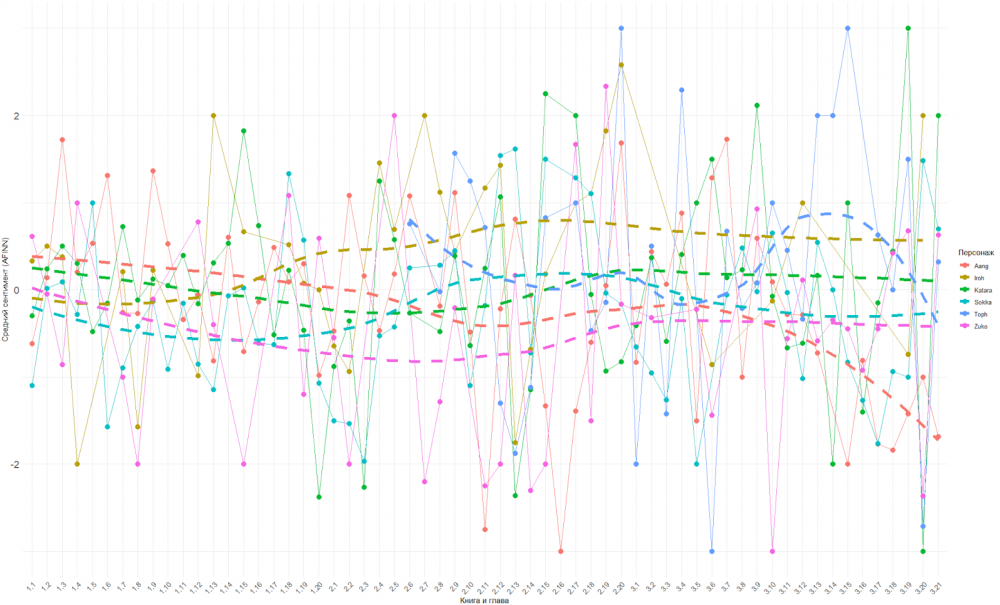
Главные положительные герои (Аанг, Сокка, Катара и Тоф), имеют относительно стабильный сентимент, который чаще колеблется около нейтральных или положительных значений, что соответствует их роли в сюжете как оптимистичных или сбалансированных персонажей.
С помощью анализа сети персонажей на основе их реплик команда изучила, кто с кем взаимодействует или кого обсуждают. Дополнительно, используя кластерные метрики, они выявили группы персонажей.
Коллегам удалось получить примерное понимание, о чем серия, выделив для каждой серии по 10 уникальных слов, которые встречаются в этом эпизоде чаще, чем в других.
«Я очень хорош»
команда: Яна Ананченкова, Дарья Баранова, Ирина Ли, Лина Макарова, Игорь Петров.
Перед командой стояла задача придумать, как можно выявить взаимодействие между персонажами, опираясь только на их диалоги. Для реализации проекта использовался датасет по мультсериалу «Аватар: Легенда об Аанге».
Основным показателем характера взаимодействий были выбраны эмоции, проявляемые в диалоге персонажей. За «диалог» были приняты каждые две подряд идущие реплики персонажей. Каждая пара реплик была векторизирована. На рисунке ниже представлены топ-20 самых часто общающихся друг с другом пар персонажей (по оси х - эмоции, по оси y - пары персонажей, синий цвет - 1, желтый цвет - 0).
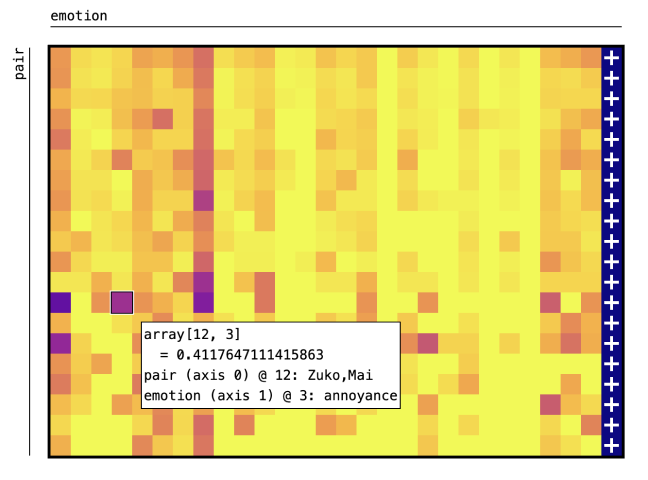
Если рассмотреть полученные результаты на примере самой контрастной 12 строчки, можно, не зная ничего о сюжете, утверждать что отношения Зуко и Мэй были неоднозначными - высокие значения у компонент, отвечающих за восхищение, раздражение, любопытство, любовь, раскаяние (интерактивный вариант рисунка представлен в коде). Значит, такие анализ и визуализация могут подсветить ключевые стороны взаимодействий для пары персонажей.
«Ничего не понятно, но очень интересно»
команда: Елизавета Асташкина, Дарья Жаркова, Елена Калинина, Вера Михальченко, Максим Тачков.
Этой команде предстояло максимально точно описать фильмы с применением техник кластеризации и тематического моделирования. Они работали на датасете из 20 киносценариев и дополнили его за счет датасета TMDB + IMDB с метаданными о сборах и наградах фильмов по этим сценариям.
Из датасета команда решила создать прототип рекомендательной системы, который изображен ниже.
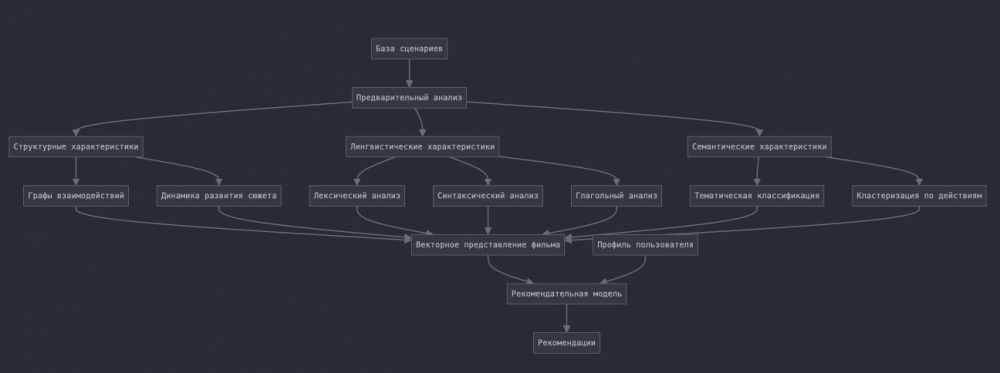
В итоговом макете рекомендательной системы можно выбрать фильм, похожий на ваш любимый фильм по сценарию или сделать выбор по следующим характеристикам:ритме повествования, количеству действующих лиц и интенсивности их взаимодействия, наличию любовных линий, наличию обсценной лексики и лексики насилия, наиболее характерных словах. Характеристика, разработанная командой, также предлагает сравнение характерных слов из сценария с фильмами того же жанра с аналогичным рейтингом.
Сценарий чувствительней сценариста?
команда проекта: Полина Воробьева, Яна Гупаисова, Катя Демидова, Полина Налобина, Антон Перфильев.
Каждый хороший ситком должен приносить приятные эмоции. Но одинаково ли они это делают? Каково соотношение хороших и негативных эмоций в ситкоме? И наконец, есть ли у ситкомов какая-то единая формула? Команда проекта попыталась ответить на все эти вопросы, используя данные сценариев сериала «Друзья» и «Теория большого взрыва».
Сначала они маркировали каждую строчку определенной эмоцией, однако это давало слишком большую долю нейтральных реплик. Так что команда решила разделить датасеты на сцены и посмотреть уже на их эмоциональность. Это радикально изменило эмоциональные кривые по сезонам. По каждому сезону они построили график эмоциональности сцен, пример такого графика на рисунке ниже: на нем видно, сколько сцен содержит каждая серия и какая эмоция преобладает в каждой из них.
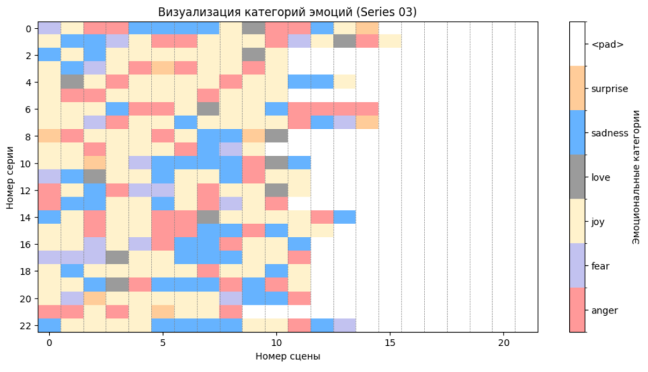
Было выявлено отсутствие корреляции между высоким рейтингом серий и нестабильностью их эмоциональной окраски.
Затем команда решила дополнительно посмотреть на лучшие и худшие серии сериала. Они заключили, что топовые и худшие эпизоды различаются как по нестабильности эмоционального состояния, по среднему количеству сцен, так и по изменениям эмоциональности сцен в целом: топовые серии имеют меньше более консистентных по эмоциям сцен. В итоге, команда пришла к выводу, что серии ситкомов и сами ситкомы достаточно уникальны.
Мы благодарим участников, приглашенных экспертов и кураторов, наших коллег за доверие и участие в воркшопе Центра МАСТ и надеемся на новые встречи!